This is a writeup of the Team 1 hackathon at Masters of Networks 2. Participants were: Benjamin Renoust, Khatuna Sandroshvili, Luca Mearelli, Federico Bo, Gaia Marcus, Kei Kreutler, Jonne Catshoek and myself. I promise you it was great fun!
The goal
We would like to learn whether groups of users in Edgeryders are self-organizing in specialized conversations, in which (a) people gravitate towards one or two topics, rather than spreading their participation effort across all topics, and (b) the people that gravitate towards a certain topic also gravitate towards each other.
Why is this relevant?
Understanding social network dynamics and learning to see the pattern of their infrastructure can become a useful tool for policy makers to rethink the way policies are developed and implemented. Furthermore, it could ensure that policies reflect both needs and possible solutions put forward by people themselves. The ability to decode linkages between members of social networks based on the areas of their specialization can allow decision makers and development organisations to:
- Tap into existing networks of knowledge and expertise to gain increased understanding of a policy issue and of the groups most affected (i.e. the target population of a policy)
- Identify pre-existing bottom-up (ideas for) solutions relevant to the policy issue at hand
- Bring together networks with a proven interest in a policy issue and leverage their engagement to design new solutions and bring about change
Compared to traditional models of policy development, this method can allow for more effective and accountable policy interventions. Rather than spending considerable resources on developing a knowledge base and building new communities around a policy theme, the methodology would enable decision makers and development organisations alike to tap into available knowledge bases and to work with these existing networks of interested specialists, saving time and resources. Moreover, pre-existing networks of specialists are expected to be more sustainable as a resource of information and collective action than ad-hoc networks built around emerging policy issues.
The data
Edgeryders is a project rolled out by the Council of Europe and the European Commission in late 2011. Its goal was to generate a proposal for the reform of European youth policy that encoded the point of view of youth themselves. This was done by launching an open conversation on an online platform (more information).
The conversation was hosted on a Drupal 6 platform. Using a Drupal module called Views Datasource, we exported three JSON files encoding respectively information about users; posts; and comments.
These data are sufficient to build the social network of the conversation. In it, users represent nodes; comments represent edges. Anna and Bob are connected by an edge if Anna has written at least one comment to a piece of content authored by Bob. We used a Python script with the Tulip library for network analysis to build the graph and analyze it. The result was a network with 260 active people and about 1600 directed edges, encoding about 4000 comments.
To move towards our goal, we needed to enrich this dataset with extra information concerning the semantics of that conversation (see below).
What we did
To define the extent to which degree people gravitate towards certain topics, and towards each other, we carried out “entanglement analysis” on a dataset containing all conversations carried out between members of the Edgeryders network. Entanglement analysis was proposed by Benjamin Renoust in 2013; we performed it using a program called Data Detangler (accessible at http://tulipposy.labri.fr:31497/).
1. Understanding Edgeryders as a social network of comments
These data can be interpreted as a social network: people write posts and comment on them; moreover, they can comment other people’s comments. Within this dataset, each comment can be interpreted as an edge, connecting the author of the comment to the author of the post or comment she is commenting on. Alternatively, we could interpret them as a bipartite network that connects people to content: comments are edges that connect their authors to the unit of content they are commenting.
2. Posts are written in response to briefs
Each of the posts written on Edgeryders is a response to set briefs, or missons, that sit under higher level campaigns. This means that many posts – and associated comments – live under the higher level ‘topic’ of one of nine campaigns.
3. Keywords indexing briefs
In order to understand how the various topics and briefs connect to each other we analysed the keywords that defined each mission/brief. This was carried out by manually analysing the significance of word frequency for each post. Word Frequency was ascertained by using the in-browser software http://tagcrowd.com/faq.html#whatis to work out the top 12-15 words per mission. We then manually verified these words and kept those that are semantically relevant (removing, for example names, or words that were too general, or that were a function of the Edgeryders platform itself- e.g. ‘comment’ or ‘add post’).
The combination of these three elements gives us a multiplex social network, that is indexed by keywords. A multiplex social network is one where there are multiple relations among the same set of actor. The process can be visualized in Figure 1.
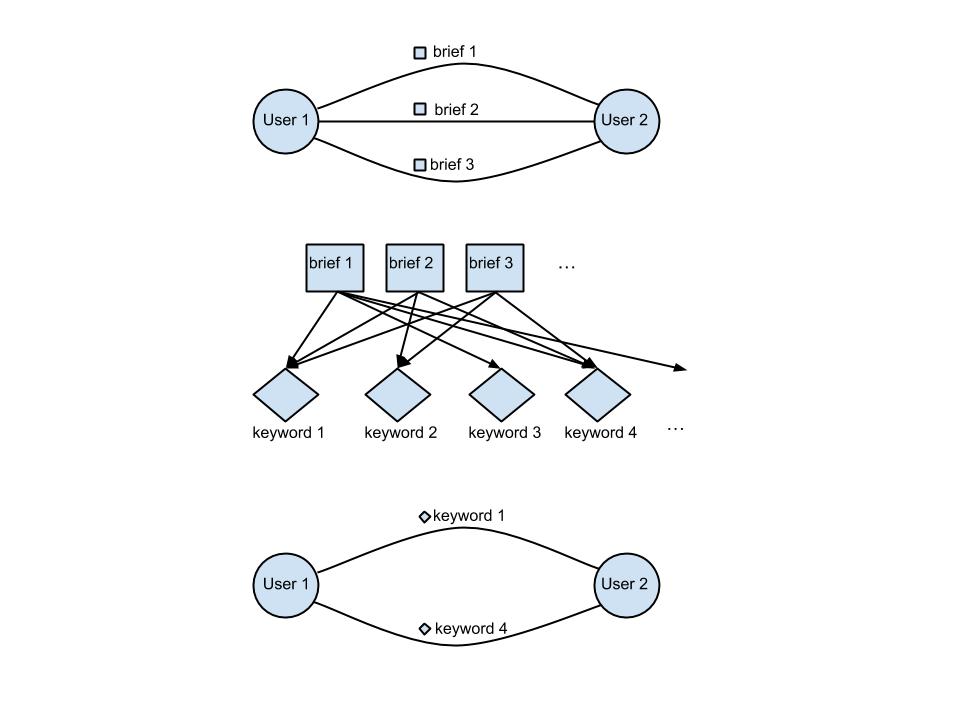 Fig. 1 – Building a multiplex social network where edges carry semantics.
Fig. 1 – Building a multiplex social network where edges carry semantics.
4. Drop one-off interactions
We dropped edges that are linked to only one brief. These are edges of “degenerate specialistic” interactions; as they only interact in the context of one brief, they are specialistic only by default.
5. Remove generalist conversations
At this point, we had a multiplex social network of users and keywords. Users were connected by edges carrying different keywords – indeed, each keyword can be seen as a “layer” of the multiplex network, inducing its own social network: the network of the conversation about employment, the network of the conversation about education etc. Many of the interactions going on are non-specialized; the same two users talk of several different things. In order to isolate specialized conversation, for each individual edge of the multiplex we remove all keywords except those that appear in all interactions between these two users. In other words, we rebuild the network by assigning to each edge the intersection of the sets of keywords encoded in each of the individual interactions. In many cases, the intersection is empty: it only takes two interactions happening in the context of two briefs with no keywords in common for this to happen. In this case, the edge is dropped altogether.
A nice side-effect of 4 and 5 is to greatly reduce the influence of the Edgeryders team of moderators on the results. Moderators are among the most active users; while this is as it should be, they tend to “skew” the behaviour of the online community. However, 4 removes all the one-off interactions they tend to have with users that are not very active; and 5 removes all the edges connecting moderators to each other, because they – by virtue of being very active – interact with one another across many different briefs, and as a result the intersection of keywords across all their interactions tends to be zero.
6. Look for groups of specialists
We then identified groups of specialists by identifying those users interacting together solely around a small number of keywords (e.g. in example, n(keywords) = 2).
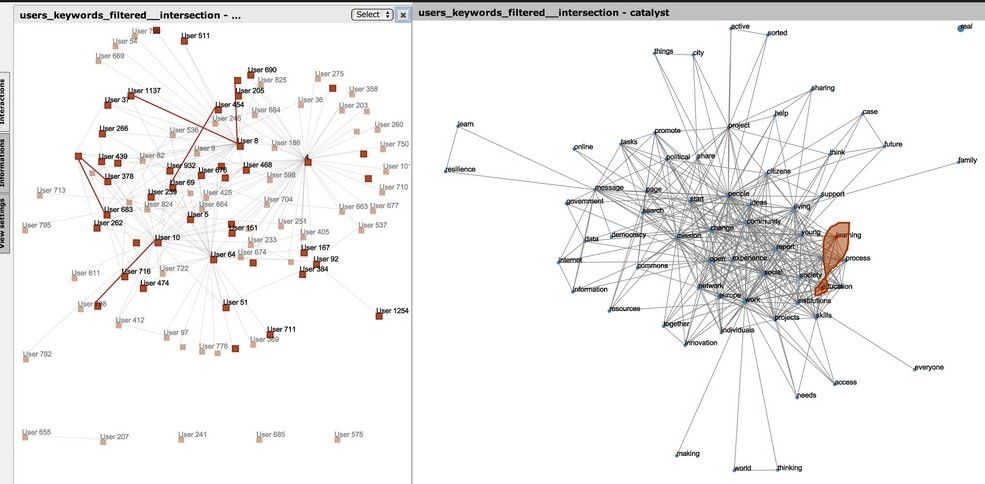 Figure 1. Detecting specialized conversations on education and learning.
Figure 1. Detecting specialized conversations on education and learning.
Conclusions
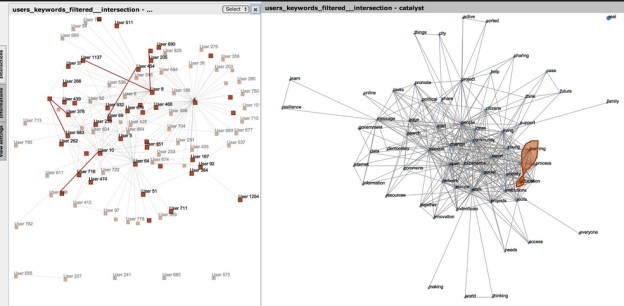
The method does indeed seem to be able to identify groups of specialists. “Groups” is used here in the social sense of a collection of people that not only write content related to the keywords, but interact with one another in doing so – this is to capture the collective intelligence dimension of large scale conversations. Figure 1 shows some conversations between people (highlighted on the left) that only interact on the “education” and “learning” keywords (shown on the right). Highlighted individuals that are not connected to any highlighted edges are users who do write contributions that are related to those keywords, but are not part to specialized interactions on those keywords.
Once a group of specialists is identified, the next step is to look for the keywords that co-occur on the edges connecting them. An example of this is Figure 2, that shows the keywords co-occurring on the edges of the conversations involving our specialist group on education and learning. The size of the edge on the right part of the figure indicated that keyword’s contribution to entanglement, i.e. to making that group of keywords a cohesive one. Unsurprisingly, “education” and “learning” are among the most important ones. More interestingly, there is another keyword that seems to be deeply entangled with these two: it is “open”. We can interpret this as follows: specialized interaction on education and learning is deeply entangled with the notion of “open”. The education specialists in this community think that openness is important when talking about education.
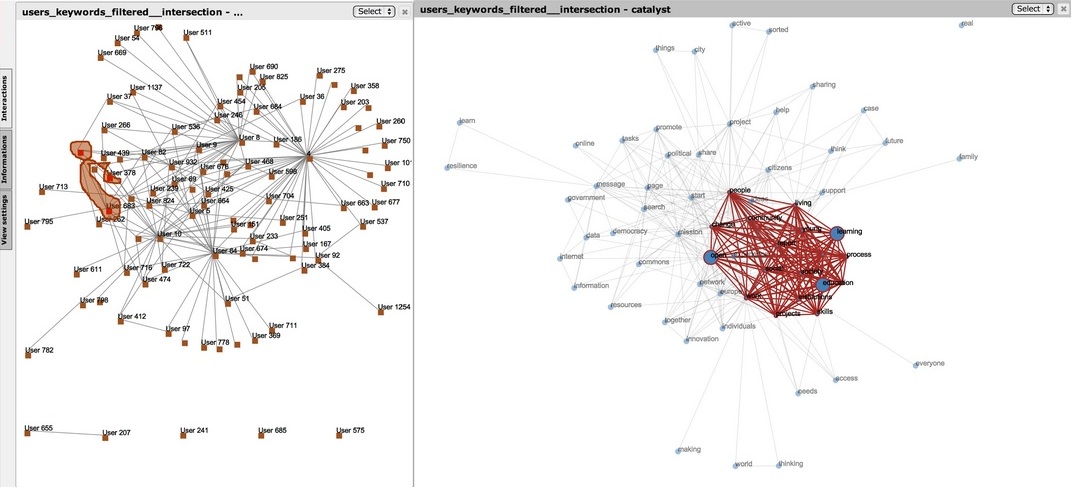 Figure 3. Discovering more keywords entangled with the original two in the specialized conversation.
Figure 3. Discovering more keywords entangled with the original two in the specialized conversation.
This method is clearly scalable. It can be used to identify “surprising” patterns of entanglement, which can then be further investigated by qualitative research.
Scope for improvement
The main problem with our method was that is is quite sensitive to the coding by keyword. Assigning the keywords was done by way of a quick hack based on occurrency count. This method should work much better with proper ethnographic coding. Note that folksonomies (unstructured tagging) typically won’t work, as it will introduce a lot of noise in the system (for example, with no stemming you get a lot of false (“degenerate”) specialist.)


{kind=link}
{kind=link}